Lambda response streaming in Go
Victor Hugo Montes
Hey there! It’s been a while since I last wrote a post, I hope I can keep up with the pace now. Today I wanted to talk about a very interesting topic related to response streaming in Go. This is a very powerful feature that allows us to send data to the client in chunks, instead of waiting for the entire response to be ready (buffered). This expands the limit of lambdas to a whole new level, allowing us to process large amounts of data without worrying about the very tiny limit of 6MB for the response payload with buffered responses.

Motivation to explore this feature
I have been trying to make myvideohunter.com to be able to download videos from Reddit. However, this time I needed to transcode the video from a playlist file (m3u8) to a single video file (mp4). As you know, the whole backbone of myvidehunter.com is serverless, so I needed to build a “transcoder” lambda that would be able to transcode the video and send the response back to the client. In a nustshell, something like this:
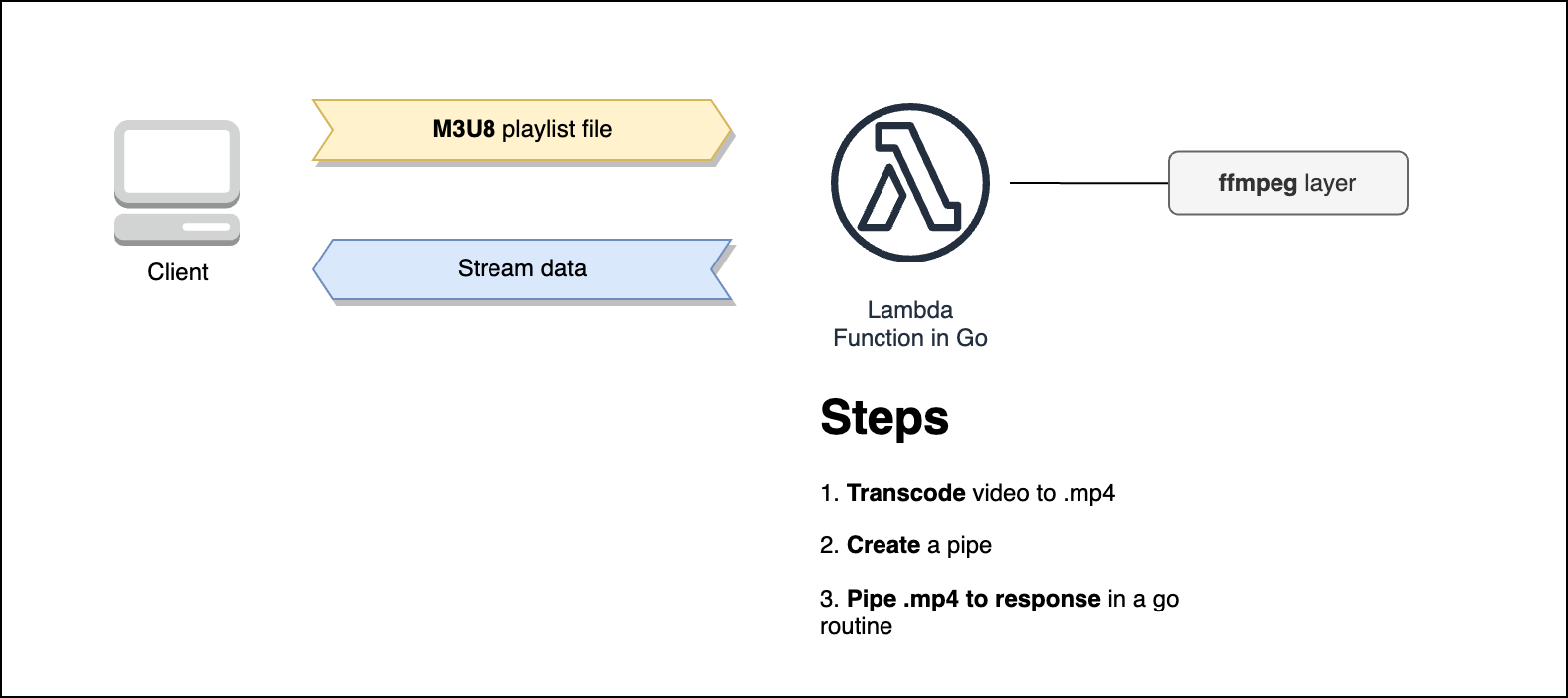
Then I stumbled on the very first limitation of buffered responses: the 6MB payload hard limit. That was limiting myvideohunter to only download videos under to 6MB, so yeah, quite small. So I needed to find a way to send the video in chunks. That’s when I found out about the new feature of response streaming in Go.
Response streaming in Go
In this AWS blog post written by Julian Wood you will find details about the announcement of AWS Lambda response streaming support. This new feature impacts positively on applications that need to send large payloads back to the client, which is the case of myvidehunter.com.
Writing a response stream in Go is very simple. You just need to make sure your handler function returns a *events.LambdaFunctionURLStreamingResponse object. This response type requires compiling with -tags lambda.norpc, or choosing the provided or provided.al2 runtime. In the example I am providing in this post, I am using the provided.al2023 runtime, which is the new Amazon Linux 2023 runtime for AWS Lambda.
Your handler fuction will look something like this:
func lambdaHandler(request *events.LambdaFunctionURLRequest) (*events.LambdaFunctionURLStreamingResponse, error) {
// Your code here
return &events.LambdaFunctionURLStreamingResponse{
StatusCode: http.StatusOK,
Headers: map[string]string{
"Content-Type": "video/mp4",
"Content-Disposition": "attachment; filename=myfile.mp4",
},
Body: r, // r is a reader.
}, nil
}
Now you can send the response back to the client in chunks in a different go routine.
IMPORTANT
You can not use Amazon API Gateway and Application Load Balancer to progressively stream response payloads. You have to stream response payloads through Lambda function URLs, including as an Amazon CloudFront origin.
Sample project
Overview of sample project
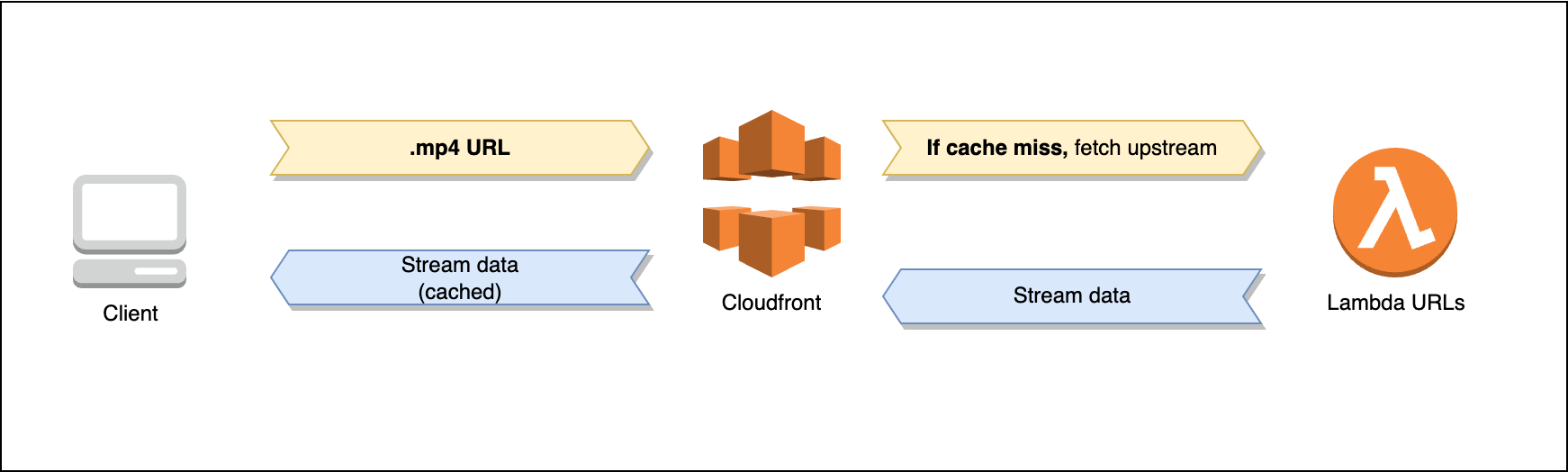
Description
I have created a sample project that you can find in my GitHub repository. This project is a simple API that returns a video file in chunks. In fact, it will return any kind of binary you request, but in the example I am returning a MP4 video file.
The scope if very simple:
The client sends a GET request to the CloudFront URL providing a URL containing the video file.
If it’s not a cache hit, CloudFront will forward the request to the Lambda function URL origin.
The Lambda will instantiate a new HTTP client, request the video file from the URL provided and pipe the client response to the response writer back to the client in a different go routine.
The client will receive the video file in chunks.
CloudFront plays a very important role in this architecture. It is the one that will cache the response from the Lambda function and serve it to the client. Each lambda invocation is very costly, so we want to avoid invoking the lambda function as much as possible.
In this example, I have created a custom cache policy with a cache key settings to include the url query parameter in the cache key. This way, if the client requests the same video file, the CloudFront will serve the response from the cache. Note that when request is served from the cache, the speed is much faster than when the request is served from the Lambda function.
How it works
This project uses the AWS Serverless Application Model (SAM) to deploy the resources to your AWS account. The project structure can be seen below:
.
├── Taskfile.yml # Tasks automation file
├── mp4tostream # Go lambda function
│ ├── go.mod
│ ├── go.sum
│ ├── main.go
│ └── main_test.go
├── samconfig.toml # SAM configuration file
└── template.yaml # SAM template file
The mp4tostream folder contains the Go lambda function that will be deployed to your AWS account. Also, in this folder we can find template.yaml which is the SAM template file that describes the resources that will be created in your account.
That’s how we configure the lambda function in the SAM template file:
Resources:
StreamingFunction:
Type: AWS::Serverless::Function
Metadata:
BuildMethod: go1.x
Properties:
CodeUri: mp4tostream/ # Path to the lambda function
Handler: bootstrap # Handler function binary
Runtime: provided.al2023 # The runtime. This one supports response streaming
Architectures:
- x86_64
Timeout: 10
FunctionUrlConfig:
AuthType: AWS_IAM # Here we define
InvokeMode: RESPONSE_STREAM
This will create a lambda function that will be able to stream the response back to the client.
Here is the handler function that will be executed when the lambda function is invoked:
func lambdaHandler(request *events.LambdaFunctionURLRequest) (*events.LambdaFunctionURLStreamingResponse, error) {
// Get url from query parameter
mp4Url := request.QueryStringParameters["url"]
log.Printf("MP4 URL to be streamed: %s\n", mp4Url)
// We will use a pipe to stream the response from the client to the response
r, w := io.Pipe()
// Prepare request
req, err := http.NewRequest(http.MethodGet, mp4Url, nil)
if err != nil {
return nil, err
}
// Perform request
resp, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
// Pipe the file to the response. This will be done in a different go routine
go func() {
defer w.Close()
defer resp.Body.Close()
if err != nil {
log.Printf("Error opening file: %v\n", err)
return
}
log.Printf("Copying response body to pipe\n")
io.Copy(w, resp.Body)
}()
return &events.LambdaFunctionURLStreamingResponse{
StatusCode: http.StatusOK,
Headers: map[string]string{
"Content-Type": "video/mp4",
"Content-Disposition": "attachment; filename=myfile.mp4",
},
Body: r,
}, nil
}
This function will request the video file from the URL provided in the query parameter and pipe the response back to the client in a different go routine.
How to deploy
To deploy the sample project, you need to have the AWS CLI and SAM CLI installed in your machine. You also need to have an AWS account and the credentials properly configured in your machine.
Tasks are automated with Tasksfile, so you can just run the following command to deploy the project:
$ tasks deploy
This command will deploy the project to your AWS account. After the deployment is finished, you will see the CloudFront URL in the output. You can use this URL to test the API.
How to test
To test the API, you can use the following command:
$ curl -o video.mp4 https://<cloudfront-url>?url=https://www.pexels.com/download/video/7230308
This command will download the video file from the URL provided and save it in a file called video.mp4.
How to remove
To remove the project from your AWS account, you can run the following command:
$ tasks remove
This command will remove all resources created by the project.
How much does it cost?
The cost of this project is zero as long as you are within the free tier limits of AWS.
Limitations
There are some limitations that you need to be aware of when using response streaming in Go:
- The maximum response payload size is 20MB. It is soft limit, and you can request a limit increase.
- The maximum execution time is 15 minutes. This is a hard limit and you can not request a limit increase.
- You can not use Amazon API Gateway and Application Load Balancer to progressively stream response payloads.
Conclusion
Response streaming in Go is a very powerful feature that allows us to send data to the client in chunks. It opens a whole new world of possibilities for serverless applications, and in my case, it allowed me to implement a transcoding fleet for myvidehunter.com only using AWS Lambda.